獨立教師
每年一到ESAT、TMUA和TARA出分的時候,我都會收到學生、家長和升學指導們對成績報告提出的各種疑問。最典型的對話通常是這樣的:
“我明明感覺自己做錯了四、五道題,但最後居然拿了8.8分!”
“我考完感覺非常好,最多只扣一、兩分,但最後成績卻只有7.3。我成績不可能這麼低。”
“我分數特別低,才4.8,這就不是我的真實水準,我懷疑系統出錯了。”
一句話:大家覺得成績報告給出的分數極其武斷、難以預測,且與實際得分完全脫節。
產生上述問題的主要原因,是大家更習慣傳統的正確率計分方式(如原始分或百分制),而對於採用複雜的拉什IRT模型(Rasch Item Response Theory Model)計算出的標準分(如1.0 – 9.0之間的分數)則很陌生,甚至無法理解。
事實上,傳統計分方式無法剔除不同試卷難易度這一干擾因素(除非像中國高考那樣不斷拉高試卷整體難度)。而採用IRT模型得出的報告分(Report Score)則徹底排除了運氣因素的干擾,能夠極其精准地測定考生的真實學術水準(尤其是精准區分中高水準的考生),從而確保招生選拔的絕對公平。
那麼,這些看似“不合常理”的報告分究竟是如何計算出來的?它又是如何捍衛牛劍選拔的絕對公平性的?接下來,我將為你硬核揭秘UAT-UK統分系統背後的IRT演算法“黑盒”。
要理解這套複雜的演算法,我們先瞭解原始分的計算方法。
ESAT、TMUA和TARA(批判思維和問題解決部分)均由選擇題構成。每道題1分,答對得1分,不答或者答錯得0分,也即答錯也不會倒扣分。最後簡單地統計所有答對的題目數量,就得到了原始分(Raw Score)。
如果全球所有考生都做同一套試卷,那麼原始分將是一個絕對公平的衡量標準。但是,現代全球統一考試的實際操作要複雜得多:為了在不同的考試日期和全球各個時區確保絕對的考試安全,UAT-UK和培生VUE必須投入多套不同的試卷版本(Forms)。
然而,面臨的現實挑戰是:要確保這些不同版本的試卷在統計學難度上保持絕對一致,是一項幾乎不可能完成的任務。
不同試卷之間的難度必然會有差異,尤其是隨著試卷套數的增加,難度差異愈發不可控。如果大學僅僅依賴原始分來錄取或發放面試邀請,那麼在一個極高難度的試卷版本中得到18分的考生,相比于在一個稍簡單的版本中得到18分的考生,就會處於極不公平的劣勢地位。為了捍衛招生過程的公平,計分方式絕不能單純的把“答對了多少題”作為唯一指標。它必須通過某種方式剔除不同試卷版本帶來的難度差異,從而還原出每個考生的真實學術水準。
為了消除試卷難度差異帶來的影響,UAT-UK採用了一套高度精確的測量框架——拉什IRT模型(Rasch Item Response Theory Model)。在IRT模型下,考生正確作答一道題目的概率是關於題目難度和考生能力的函數。隨著考生能力的增加,其正確作答題目的概率也相應的增加。在Rasch公式中,第$j$-th個考生正確作答第$i$-th道題目的$P_{ij}$概率被定義為:
$$P_{ij}=\frac{exp(\theta_{j}-b_{i})}{1+exp(\theta_{j}-b_{i})}$$
(編者注:UAT-UK官方報告中給出的Rasch概率計算公式有印刷錯誤。)
其中,$\theta_j$表示第$j$-th個考生的能力,$b_i$表示第$i$-th道題目的難度。$\theta$(能力)和$b$(難度)這兩個參數各自採用統一的度量標準,$\theta$越大表示能力越強,而$b$越大則表示題目越難。
以某一套試題為例,考試結束後,UAT-UK即獲得了所有作答這套試題的考生的原始分,但這些原始分並不能代表考生的真實能力($\theta$)。爲了計算出真實的$\theta$值。系統會借助Winsteps軟件進行極為複雜的反覆運算計算——這是一場精密的數學平衡術。
第一步
設定初始預估值
第二步
計算期望分數
第三步
微調$\theta$值
第四步
微調$b$值
第五步
循環直至$\theta$值和$b$值收斂
第六步
確定所有考生的$\theta$值
這樣一套循環迭代運算過程想想都覺得複雜,整個過程計算下來更是需要耗費大量的時間。這也是為什麼ESAT、TMUA、TARA這些考試的原始分可以在考後立即得出,但報告分卻要在幾周之後才能得出的原因。
人們總是理所當然地認為,難題比簡單題會獲得加分或更高的權重。但在ESAT、TMUA和TARA所使用的IRT模型下,這種想法是完全錯誤的。從上述反覆運算計算過程可以看出,IRT模型徹底抵消了因抽到“困難卷”或“簡單卷”而帶來的不公,所有考生的能力($\theta$值)都可以在同一個標準上進行比較。
此外,IRT模型是基於整張試卷答對所有題目的概率之和來評估考生能力($\theta$值)的。它不看考生具體的答題模式:如果一個考生粗心做錯了一道極簡單的題,但運氣爆棚蒙對了一道極難的題,演算法並不會認為這是一個潛在的天才。在統計學上,做錯簡單題的“粗心”和做對難題的“幸運”兩者相互抵消,所以演算法並不在乎考生具體答對了哪些題,它只在乎考生答對題目的總數量。從這個角度來看,試卷上的每一道題,無論難易程度,在推高考生能力($\theta$值)的權重上,效力幾乎是等同的。
由此得出的終極結論是:對於同一套特定難度的試卷而言,在剔除了具體題目的難度權重後,考生最終的底層能力($\theta$值)實際上取決於其答對題目的總數量。這就意味著,試圖通過在考場上死磕某一道或幾道難題來“套路”系統,是一種極其錯誤的策略。最理智的應試策略永遠是——在有限的時間內,確保答對盡可能多的題目。
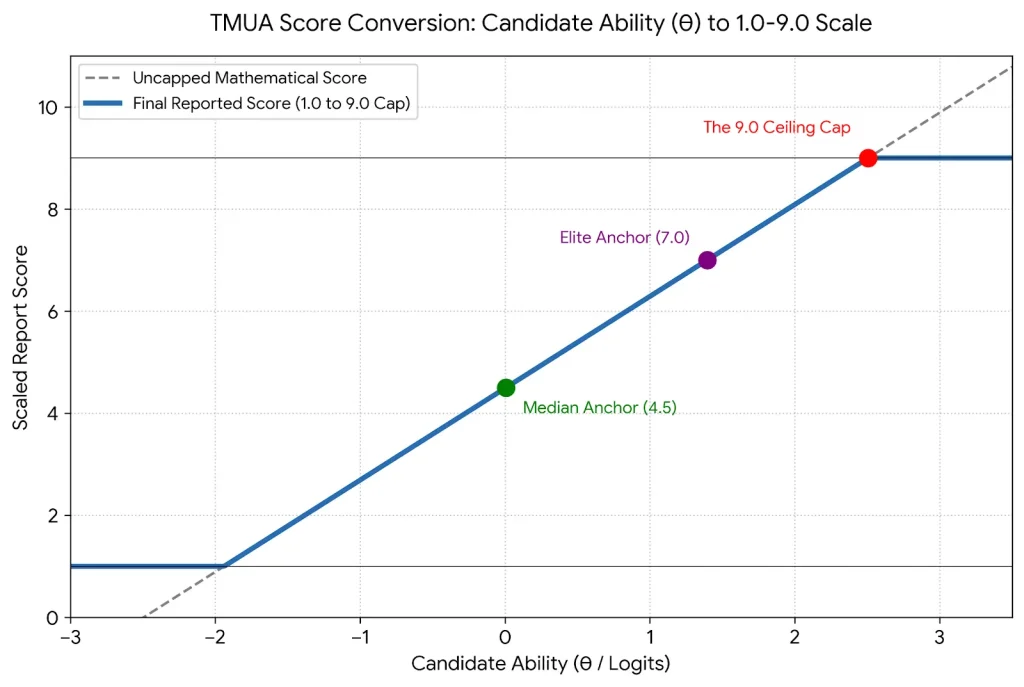
一旦IRT演算法鎖定了考生能力($\theta$值),複雜且耗時的反覆運算計算就結束了。然而,未經處理的$\theta$值對大學招生官來說並不直觀,家長和學生也很難看懂。因為$\theta$值的範圍通常在-3.0到+3.0之間,且包含一串串小數。UAT-UK必須將其轉化為標準化的、用戶友好的格式。這就是經典的1.0至9.0報告分的由來了。
為了保證整個招生週期的絕對一致性,UAT-UK要求報告分必須錨定當年考生的實際水平。所以他們設定了兩個固定錨點:
排名位於正中間位置(50百分位)考生能力($\theta$值),被強制設定為4.5分。
處於前10%分水嶺(90百分位)考生能力($\theta$值),被強制設定為7.0分。
以2024年10月的TMUA考試為例,這兩個固定錨定對應的考生能力和報告分如下表所示:
錨定這兩個基準點後,系統就能計算出對應的線性回歸方程的截距(Constant)與回歸係數(Multiplier):
隨後,系統會將每個考生的($\theta$值)代入該方程,在一條連續的回歸直線上推導出轉換後的分數,如下圖所示:
TMUA分數轉換曲線圖
(考生能力($\theta$值)轉化到1.0-9.0報告分的連續線性回歸過程) value) into a 1.0–9.0 report score)
Finally, two rules must be followed when deriving the final report score:
考生的分數會被四捨五入到小數點後一位(例如,6.4732 會變成 6.5)。
The upper limit for scores is 9.0; scores exceeding 9.0 are recorded as 9.0. The lower limit is 1.0; scores below 1.0 are recorded as 1.0.
這三項考試最終給出的成績報告有差異,並不都是只給出一個報告分。
TMUA的成績報告
儘管TMUA考試分為兩張試卷,試卷一和試卷二各20道題,但官方給出的是一個單一的報告分(1.0至9.0),相當於總分,並沒有針對每張試卷給出獨立的報告分。
ESAT的成績報告
ESAT的5個模組都是完全獨立的,成績報告給出每個模組的報告分,但不會提供類似TMUA那樣的總分。
TARA的成績報告
TARA的批判思維和問題解決這兩個部分是選擇題,成績報告中分別給出這兩個部分各自的報告分,但並不會針對批判寫作部分算分。考試局會將考試的寫作部分原稿直接發送給大學招生官,由他們主觀評估考生構建嚴謹學術論證的能力。
儘管前文已經詳細闡述了IRT演算法和報告分是如何得出的,但各位學生、老師和家長可能還是會有以下三大疑問。接下來我將一一為大家解謎。
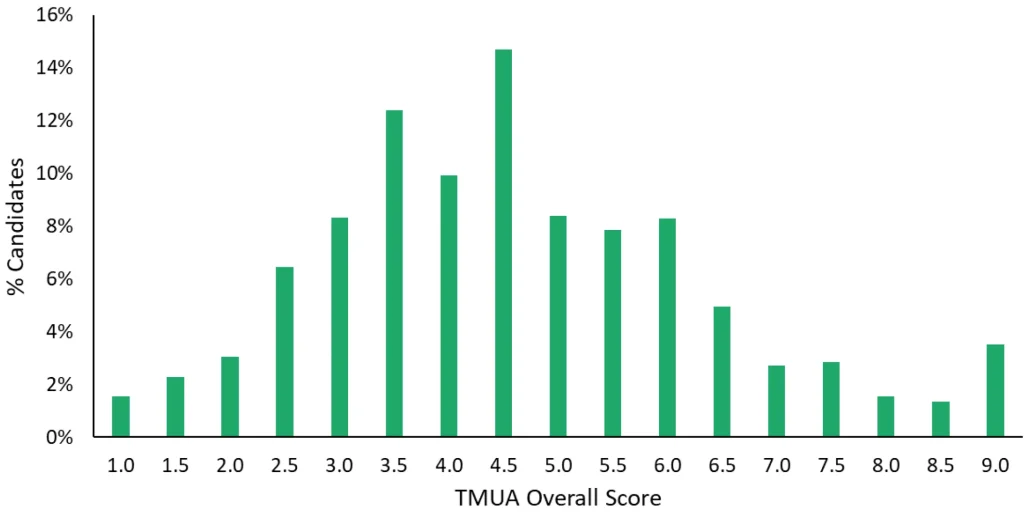
一個常見的、反直覺的現象就是9.0分考生的比例出奇的高!如下圖所示:
UAT-UK官方報告截圖:2025年10月TMUA的全球成績分佈
(“分數封頂”規則會導致1.0分和9.0分的考生比例異常高)
在2025年10月TMUA考試的成績分佈中,9.0分的考生比例甚至比8.0和8.5兩個分數段的考生比例之和還要高。事實上,對於一場TMUA考試,兩張試卷合計40道題,在沒有9.0分封頂的情況下,原始分35分可能對應報告分8.8分,36分對應9.2分,而如果是滿分40分,其考生能力換算出的未封頂分數甚至可能突破12分!但在殘酷的“封頂規則”下,這些已經超出9.0邊界的頂尖學霸,在成績單上統統只顯示9.0分。因此,你在圖表中看到的龐大的9.0分陣營,其實折疊了無數個數學能力遠超天花板的曠世奇才。
UAT-UK為什麼要這麼做?
不難理解,入學考試的設計初衷是“甄別能力是否達到了特定門檻”,而不是去精確衡量無窮無盡的極限天賦。9.0分的上限向大學釋放了一個明確的信號:該考生已經徹底掌握了本試卷考查的所有內容。將這些頂尖學生全部歸入9.0分那一檔,在統計學上遠比一套40題的試卷能精確測定天才(39/40)和曠世奇才(40/40)之間的認知差距要安全、可靠得多。
這個困惑來自於兩方面。一是官方給出的成績報告,居然有某個區間的成績沒有任何考生能達到。如下圖所示:
UAT-UK官方報告截圖:2025年10月ESAT化學的全球成績分佈
(The discrete score conversion curve makes it impossible for candidates to obtain certain scores)
而另一方面,當一個考生成績為8.3分,另一位考生是8.8分時,大家會很自然地猜測:肯定有人考了8.4、8.5、8.6或8.7。不管上述哪種情況,給人的感覺就是某些特定的分數好像消失了一樣。
事實上,對於一套特定的試卷而言,絕大部分的中間分數確實是不存在的。以ESAT為例,一個模組有27道題,考生的原始分只能是整數(如24或25分),不會出現24.1、24.5這類帶小數點的分數。而同一套試卷的原始分跟考生能力是一一對應的關係。所以,原始分的28種可能性(包含0分),也就對應28個不同的考生能力(值),然後對照分數轉換曲線相應的換算出28個帶小數點的報告分。
下面這個視覺化模擬器演示了兩種不同難度試卷的原始分和報告分之間的換算關係。從中可以很直觀的看到:分數換算曲線是離散的,並不是1.0到9.0之間所有的分數都能得到。
原始分和報告分之間的換算視覺化模擬器
(不同試卷對ESAT報告分的影響)
請選擇一個原始分,查看試卷的原始分和報告分之間的換算關係,以及不同難度的試卷如何影響考生最終的報告分。
0.0
從上面的分數轉換曲線示例可以看到,難易程度不同的兩份試卷,同樣做對19道題,試卷A(稍難一點)的報告分是5.7,而試卷B(稍容易一點)的報告分只有4.9。相差的0.8分,在頂尖名校的申請池中,基本就是“被錄取”與“被淘汰”的天壤之別。而試卷B的考生若想追平這5.7分,必須在考場上多答對整整3道題!所以,所謂的“同分不同命”,在IRT演算法下被體現得淋漓盡致。
在瞭解了複雜的IRT演算法後,家長和學生通常會產生一個更具戰略性的疑問:既然存在多套試卷,那麼不同地區的成績分佈是一樣的嗎?中國考生的7分和英國考生的7分,在招生官眼中含金量是否對等?
答案是:完全不一樣。
根據UAT-UK公佈的2024/25申請季官方資料,全球不同國籍與地區在TMUA考試中的表現呈現出巨大的斷層 。
TMUA部分區域成績分佈(2024/25申請季)
* 數據來源:UAT-UK官方報告
從上表中可以挖掘出一個殘酷的事實:中國考生的“平均水準”,即是英國考生的“頂尖水準”。
中國考生的中位數(5.4分)已經直逼英國考生的前10%門檻(5.8分)。這意味著一個中等的中國考生,其數學素養在英國本土生源中可能已是佼佼者。而對於中國志在牛劍的頂級學霸來說,競爭對手不是全球考生,而是那群將90百分位線推高至 8.4分的同胞 。這2.6分的落差,就是中國學生為了抵消區域生源內卷而必須承受的“高分溢價”。
中英考生ESAT各模組成績對比(2024/25申請季)
同樣的內卷壓力在ESAT考試中體現得更為具體。以下是英國與中國考生在各模組的表現差異:
在數學1、數學2和物理模組中,中國考生的前10%分數均在8.0分以上,而英國考生對應的分數僅在5.6至6.0分之間。這再次證明中國考生在純理科邏輯領域具有絕對優勢,但也意味著在這個賽道上,中國考生幾乎沒有任何犯錯的空間,必須追求極致的高分才能在招生官面前脫穎而出。
生物模組的“戰略藍海”
值得關注的是,生物是中英表現差距最小的科目。在生物模組中,中國前10%(7.6分)與英國前10%(7.0分)的差距僅為0.6分。這反映出生物學科對綜合素質、語言理解和學科積累有更高要求。對於理科底蘊深厚且具備生物背景的中國學生,選擇生物模組或許是一個避開數學、物理極端內卷、實現“差異化競爭”的有效路徑。
在英國頂尖大學為各個區域分配名額有限的大環境下,中國、中國香港、新加坡等地區的考生必須面對更嚴苛的篩選標準,其目標不應僅僅是“過線”,而是必須取得“高分中的高分”。
在透徹理解了UAT-UK這三項考試換算分的底層演算法和邏輯之後,我們得出了以下幾個決定考生命運的核心結論 :
報告分本質是“排名”而非“絕對分”。IRT模型剝離了運氣成分,徹底抵消了不同試卷版本產生的難度差異。最終呈現在成績報告上的1.0-9.0分,反映的是考生在剝離所有外部干擾後的真實能力,它通過標準化的方式直接且殘酷地反映了考生在群體中的精確排名。考生不是在和某一張試卷較勁,而是在和全球的最強大腦搶奪那條代表前10%的基準線(7.0分)。
在考場上,與其把時間耗在思考怎麼做對幾道極品難題,不如把戰略重心放在“怎麼做對更多的題”上。原因在於IRT演算法下存在一個極其反直覺的現象:
不要慌張。難度越高的試卷,其實容錯率越高。哪怕你有三道變態難題完全沒思路,只要穩住基本盤,確保該拿的分不丟,依然有可能拿到9.0滿分。
難度越低的試卷,容錯率越低。如果試卷很簡單,因為粗心大意錯了一道基本題,可能就會被直接扣到8.3分,瞬間跌出牛劍第一梯隊。
上述殘酷的換算分結論,與優易長期以來堅持的課程研發理念和採取的備考策略高度契合。既然系統無法被“套路”,機械的刷題就失去了意義。我們強調,必須將核心精力放在培養和提升學生真正的數學成熟度和批判思維水準上。只有當他們具備了嚴謹的思維方式,以及應對和解決陌生新題型的硬核能力時,能力才會產生質的飛躍。當他們的真實能力遠遠越過7.0的錨點,無論UAT-UK拋出什麼難度的試卷,對其他考生都會是一場降維打擊。
為了幫助大家更精准地應對不同考試的特點,針對UAT-UK的每一項考試,我都有結合最新實考數據專門撰寫相應的深度備考指南,歡迎各位進一步閱讀:
Comprehensive ESAT Guide
TMUA考試全面解讀
TARA考試全面解讀