独立教师
每年一到ESAT、TMUA和TARA出分的时候,我都会收到学生、家长和升学指导们对成绩报告提出的各种疑问。最典型的对话通常是这样的:
“我明明感觉自己做错了四、五道题,但最后居然拿了8.8分!”
“我考完感觉非常好,最多只扣一、两分,但最后成绩却只有7.3。我成绩不可能这么低。”
“我分数特别低,才4.8,这就不是我的真实水平,我怀疑系统出错了。”
一句话:大家觉得成绩报告给出的分数极其武断、难以预测,且与实际得分完全脱节。
产生上述问题的主要原因,是大家更习惯传统的正确率计分方式(如原始分或百分制),而对于采用复杂的拉什IRT模型(Rasch Item Response Theory Model)计算出的标准分(如1.0 – 9.0之间的分数)则很陌生,甚至无法理解。
事实上,传统计分方式无法剔除不同试卷难易度这一干扰因素(除非像中国高考那样不断拉高试卷整体难度)。而采用IRT模型得出的报告分(Report Score)则彻底排除了运气因素的干扰,能够极其精准地测定考生的真实学术水平(尤其是精准区分中高水平的考生),从而确保招生选拔的绝对公平。
那么,这些看似“不合常理”的报告分究竟是如何计算出来的?它又是如何捍卫牛剑选拔的绝对公平性的?接下来,我将为你硬核揭秘UAT-UK统分系统背后的IRT算法“黑盒”。
要理解这套复杂的算法,我们先了解原始分的计算方法。
ESAT、TMUA和TARA(批判思维和问题解决部分)均由选择题构成。每道题1分,答对得1分,不答或者答错得0分,也即答错也不会倒扣分。最后简单地统计所有答对的题目数量,就得到了原始分(Raw Score)。
如果全球所有考生都做同一套试卷,那么原始分将是一个绝对公平的衡量标准。但是,现代全球统一考试的实际操作要复杂得多:为了在不同的考试日期和全球各个时区确保绝对的考试安全,UAT-UK和培生VUE必须投入多套不同的试卷版本(Forms)。
然而,面临的现实挑战是:要确保这些不同版本的试卷在统计学难度上保持绝对一致,是一项几乎不可能完成的任务。
不同试卷之间的难度必然会有差异,尤其是随着试卷套数的增加,难度差异愈发不可控。如果大学仅仅依赖原始分来录取或发放面试邀请,那么在一个极高难度的试卷版本中得到18分的考生,相比于在一个稍简单的版本中得到18分的考生,就会处于极不公平的劣势地位。为了捍卫招生过程的公平,计分方式绝不能单纯的把“答对了多少题”作为唯一指标。它必须通过某种方式剔除不同试卷版本带来的难度差异,从而还原出每个考生的真实学术水平。
为了消除试卷难度差异带来的影响,UAT-UK采用了一套高度精确的测量框架——拉什IRT模型(Rasch Item Response Theory Model)。在IRT模型下,考生正确作答一道题目的概率是关于题目难度和考生能力的函数。随着考生能力的增加,其正确作答题目的概率也相应的增加。在Rasch公式中,第$j$个考生正确作答第$i$道题目的概率$P_{ij}$被定义为:
$$P_{ij}=\frac{exp(\theta_{j}-b_{i})}{1+exp(\theta_{j}-b_{i})}$$
(编者注:UAT-UK官方报告中给出的Rasch概率计算公式有印刷错误。)
其中,$\theta_j$表示第$j$个考生的能力,$b_i$表示第$i$道题目的难度。$\theta$(能力)和$b$(难度)这两个参数各自采用统一的度量标准,$\theta$越大表示能力越强,而$b$越大则表示题目越难。
以某一套试题为例,考试结束后,UAT-UK即获得了所有作答这套试题的考生的原始分,但这些原始分并不能代表考生的真实能力($\theta$)。为了计算出真实的$\theta$值,系统会借助Winsteps软件进行极为复杂的迭代计算——这是一场精密的数学平衡术。
第一步
设定初始预估值
第二步
计算期望分数
第三步
微调$\theta$
第四步
微调$b$值
第五步
循环直至$\theta$值和$b$值收敛
第六步
确定所有考生的$\theta$值
这样一套循环迭代过程想想都觉得复杂,整个过程计算下来更是需要耗费大量的时间。这也是为什么ESAT、TMUA、TARA这些考试的原始分可以在考后立即得出,但报告分却要在几周之后才能得出的原因。
人们总是理所当然地认为,难题比简单题会获得加分或更高的权重。但在ESAT、TMUA和TARA所使用的IRT模型下,这种想法是完全错误的。从上述迭代计算过程可以看出,IRT模型彻底抵消了因抽到“困难卷”或“简单卷”而带来的不公,所有考生的能力($\theta$值)都可以在同一个标尺上进行比较。
此外,IRT模型是基于整张试卷答对所有题目的概率之和来评估考生能力($\theta$值)的。它不看考生具体的答题模式:如果一个考生粗心做错了一道极简单的题,但运气爆棚蒙对了一道极难的题,算法并不会认为这是一个潜在的天才。在统计学上,做错简单题的“粗心”和做对难题的“幸运”两者相互抵消,所以算法并不在乎考生具体答对了哪些题,它只在乎考生答对题目的总数量。从这个角度来看,试卷上的每一道题,无论难易程度,在推高考生能力($\theta$值)的权重上,效力几乎是等同的。
由此得出的终极结论是:对于同一套特定难度的试卷而言,在剔除了具体题目的难度权重后,考生最终的底层能力($\theta$值)实际上取决于其答对题目的总数量。这就意味着,试图通过在考场上死磕某一道或几道难题来“套路”系统,是一种极其错误的策略。最理智的应试策略永远是——在有限的时间内,确保答对尽可能多的题目。
一旦IRT算法锁定了考生能力($\theta$值),复杂且耗时的迭代计算就结束了。然而,未经处理的值对大学招生官来说并不直观,家长和学生也很难看懂。因为值的范围通常在-3.0到+3.0之间,且包含一串串小数。UAT-UK必须将其转化为标准化的、用户友好的格式。这就是经典的1.0至9.0报告分的由来了。
为了保证整个招生周期的绝对一致性,UAT-UK要求报告分必须锚定当年考生的实际水平。所以他们设定了两个固定锚点:
排名位于正中间位置(50百分位)考生能力(值),被强制设定为4.5分。
处于前10%分水岭(90百分位)考生能力(值),被强制设定为7.0分。
以2024年10月的TMUA考试为例,这两个固定锚定对应的考生能力和报告分如下表所示:
锚定这两个基准点后,系统就能计算出对应的线性回归方程的截距(Constant)与回归系数(Multiplier):
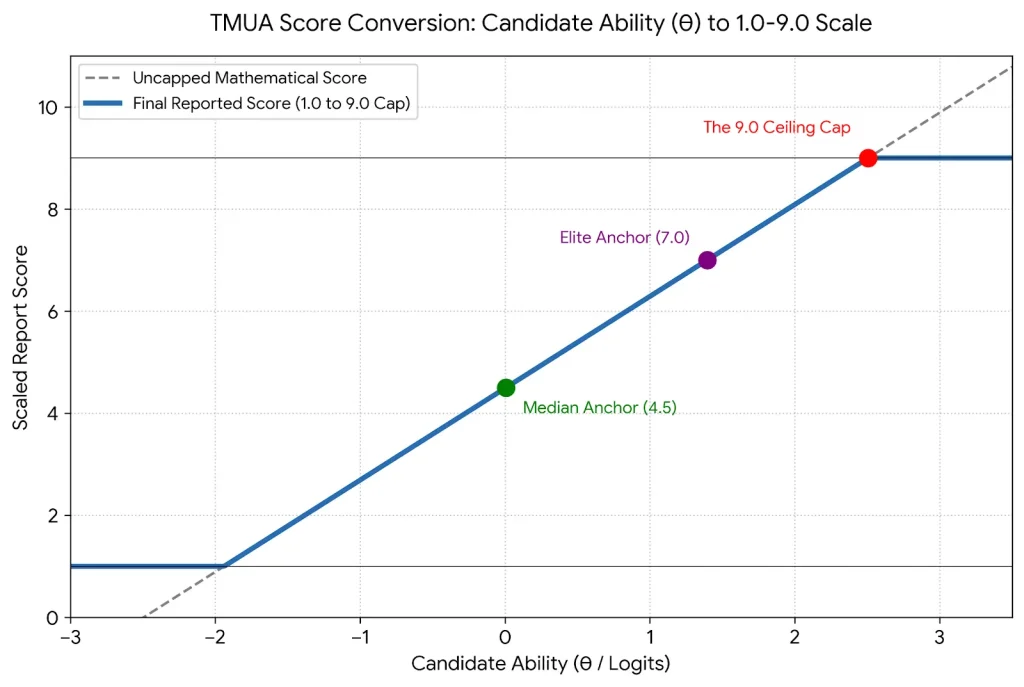
随后,系统会将每个考生的($\theta$值)代入该方程,在一条连续的回归直线上推导出转换后的分数,如下图所示:
TMUA分数转换曲线图
(考生能力($\theta$值)转化到1.0-9.0报告分的连续线性回归过程)
最后,在得出最终的报告分时还要遵循两条规则:
考生的分数会被四舍五入到小数点后一位(例如,6.4732 会变成 6.5)。
分数上限是9.0,超过9.0的分数记为9.0;分数下限是1.0,低于1.0的分数记为1.0。
这三项考试最终给出的成绩报告有差异,并不都是只给出一个报告分。
TMUA的成绩报告
尽管TMUA考试分为两张试卷,试卷一和试卷二各20道题,但官方给出的是一个单一的报告分(1.0至9.0),相当于总分,并没有针对每张试卷给出独立的报告分。
ESAT的成绩报告
ESAT的5个模块都是完全独立的,成绩报告给出每个模块的报告分,但不会提供类似TMUA那样的总分。
TARA的成绩报告
TARA的批判思维和问题解决这两个部分是选择题,成绩报告中分别给出这两个部分各自的报告分,但并不会针对批判写作部分算分。考试局会将考试的写作部分原稿直接发送给大学招生官,由他们主观评估考生构建严谨学术论证的能力。
尽管前文已经详细阐述了IRT算法和报告分是如何得出的,但各位学生、老师和家长可能还是会有以下三大疑问。接下来我将一一为大家解谜。
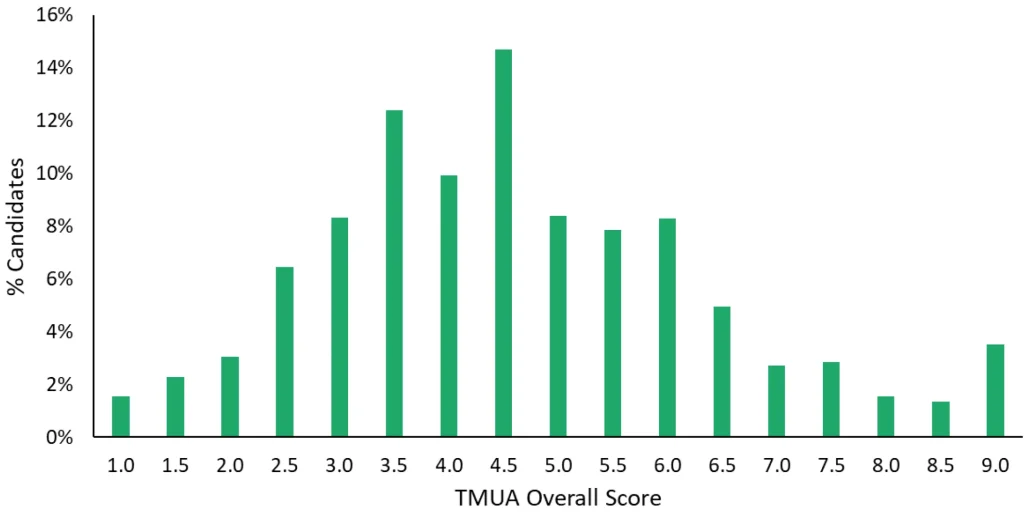
一个常见的、反直觉的现象就是9.0分考生的比例出奇的高!如下图所示:
UAT-UK官方报告截图:2025年10月TMUA的全球成绩分布
(“分数封顶”规则会导致1.0分和9.0分的考生比例异常高)
在2025年10月TMUA考试的成绩分布中,9.0分的考生比例甚至比8.0和8.5两个分数段的考生比例之和还要高。事实上,对于一场TMUA考试,两张试卷合计40道题,在没有9.0分封顶的情况下,原始分35分可能对应报告分8.8分,36分对应9.2分,而如果是满分40分,其考生能力换算出的未封顶分数甚至可能突破12分!但在残酷的“封顶规则”下,这些已经超出9.0边界的顶尖学霸,在成绩单上统统只显示9.0分。因此,你在图表中看到的庞大的9.0分阵营,其实折叠了无数个数学能力远超天花板的旷世奇才。
UAT-UK为什么要这么做?
不难理解,入学考试的设计初衷是“甄别能力是否达到了特定门槛”,而不是去精确衡量无穷无尽的极限天赋。9.0分的上限向大学释放了一个明确的信号:该考生已经彻底掌握了本试卷考查的所有内容。将这些顶尖学生全部归入9.0分那一档,在统计学上远比一套40题的试卷能精确测定天才(39/40)和旷世奇才(40/40)之间的认知差距要安全、可靠得多。
这个困惑来自于两方面。一是官方给出的成绩报告,居然有某个区间的成绩没有任何考生能达到。如下图所示:
UAT-UK官方报告截图:2025年10月ESAT化学的全球成绩分布
(离散的分数换算曲线导致考生无法取得某些分数)
而另一方面,当一个考生成绩为8.3分,另一位考生是8.8分时,大家会很自然地猜测:肯定有人考了8.4、8.5、8.6或8.7。不管上述哪种情况,给人的感觉就是某些特定的分数好像消失了一样。
事实上,对于一套特定的试卷而言,绝大部分的中间分数确实是不存在的。以ESAT为例,一个模块有27道题,考生的原始分只能是整数(如24或25分),不会出现24.1、24.5这类带小数点的分数。而同一套试卷的原始分跟考生能力是一一对应的关系。所以,原始分的28种可能性(包含0分),也就对应28个不同的考生能力(值),然后对照分数转换曲线相应的换算出28个带小数点的报告分。
下面这个可视化模拟器演示了两种不同难度试卷的原始分和报告分之间的换算关系。从中可以很直观的看到:分数换算曲线是离散的,并不是1.0到9.0之间所有的分数都能得到。
原始分和报告分之间的换算可视化模拟器
(不同试卷对ESAT报告分的影响)
请选择一个原始分,查看试卷的原始分和报告分之间的换算关系,以及不同难度的试卷如何影响考生最终的报告分。
0.0
从上面的分数转换曲线示例可以看到,难易程度不同的两份试卷,同样做对19道题,试卷A(稍难一点)的报告分是5.7,而试卷B(稍容易一点)的报告分只有4.9。相差的0.8分,在顶尖名校的申请池中,基本就是“被录取”与“被淘汰”的天壤之别。而试卷B的考生若想追平这5.7分,必须在考场上多答对整整3道题!所以,所谓的“同分不同命”,在IRT算法下被体现得淋漓尽致。
在了解了复杂的IRT算法后,家长和学生通常会产生一个更具战略性的疑问:既然存在多套试卷,那么不同地区的成绩分布是一样的吗?中国考生的7分和英国考生的7分,在招生官眼中含金量是否对等?
答案是:完全不一样。
根据UAT-UK公布的2024/25申请季官方数据,全球不同国籍与地区在TMUA考试中的表现呈现出巨大的断层 。
TMUA部分区域成绩分布(2024/25申请季)
* 数据来源:UAT-UK官方报告
从上表中可以挖掘出一个残酷的事实:中国考生的“平均水平”,即是英国考生的“顶尖水平”。
中国考生的中位数(5.4分)已经直逼英国考生的前10%门槛(5.8分)。这意味着一个中等的中国考生,其数学素养在英国本土生源中可能已是佼佼者。而对于中国志在牛剑的顶级学霸来说,竞争对手不是全球考生,而是那群将90百分位线推高至 8.4分的同胞 。这2.6分的落差,就是中国学生为了抵消区域生源内卷而必须承受的“高分溢价”。
中英考生ESAT各模块成绩对比(2024/25申请季)
同样的内卷压力在ESAT考试中体现得更为具体。以下是英国与中国考生在各模块的表现差异:
在数学1、数学2和物理模块中,中国考生的前10%分数均在8.0分以上,而英国考生对应的分数仅在5.6至6.0分之间。这再次证明中国考生在纯理科逻辑领域具有绝对优势,但也意味着在这个赛道上,中国考生几乎没有任何犯错的空间,必须追求极致的高分才能在招生官面前脱颖而出。
生物模块的“战略蓝海”
值得关注的是,生物是中英表现差距最小的科目。在生物模块中,中国前10%(7.6分)与英国前10%(7.0分)的差距仅为0.6分。这反映出生物学科对综合素质、语言理解和学科积累有更高要求。对于理科底蕴深厚且具备生物背景的中国学生,选择生物模块或许是一个避开数学、物理极端内卷、实现“差异化竞争”的有效路径。
在英国顶尖大学为各个区域分配名额有限的大环境下,中国、中国香港、新加坡等地区的考生必须面对更严苛的筛选标准,其目标不应仅仅是“过线”,而是必须取得“高分中的高分”。
在透彻理解了UAT-UK这三项考试换算分的底层算法和逻辑之后,我们得出了以下几个决定考生命运的核心结论 :
报告分本质是“排名”而非“绝对分”。IRT模型剥离了运气成分,彻底抵消了不同试卷版本产生的难度差异。最终呈现在成绩报告上的1.0-9.0分,反映的是考生在剥离所有外部干扰后的真实能力,它通过标准化的方式直接且残酷地反映了考生在群体中的精确排名。考生不是在和某一张试卷较劲,而是在和全球的最强大脑抢夺那条代表前10%的基准线(7.0分)。
在考场上,与其把时间耗在思考怎么做对几道极品难题,不如把战略重心放在“怎么做对更多的题”上。原因在于IRT算法下存在一个极其反直觉的现象:
不要慌张。难度越高的试卷,其实容错率越高。哪怕你有三道变态难题完全没思路,只要稳住基本盘,确保该拿的分不丢,依然有可能拿到9.0满分。
难度越低的试卷,容错率越低。如果试卷很简单,因为粗心大意错了一道基本题,可能就会被直接扣到8.3分,瞬间跌出牛剑第一梯队。
上述残酷的换算分结论,与优易长期以来坚持的课程研发理念和采取的备考策略高度契合。既然系统无法被“套路”,机械的刷题就失去了意义。我们强调,必须将核心精力放在培养和提升学生真正的数学成熟度和批判思维水平上。只有当他们具备了严谨的思维方式,以及应对和解决陌生新题型的硬核能力时,能力才会产生质的飞跃。当他们的真实能力远远越过7.0的锚点,无论UAT-UK抛出什么难度的试卷,对其他考生都会是一场降维打击。
为了帮助大家更精准地应对不同考试的特点,针对UAT-UK的每一项考试,我都有结合最新实考数据专门撰写相应的深度备考指南,欢迎各位进一步阅读:
ESAT考试全面解读
TMUA考试全面解读
TARA考试全面解读